A tuple tree contains all data for a particular tuple in the database. It represents data from all the joined relational tables described by the associated schema tree. Structurally, it is an exact duplicate of the schema tree with a level of instance nodes placed after each level of attribute nodes (including the leaves).
The tuple tree allows programs to manipulate entire sets of related rows with simple operations. We can view, add, delete, or modify branches. We can produce rows relating to a branch by traversing only the part of the tree that is of interest.
For example, an application might create a new branch of a tuple tree. Each attribute is initialized to have a single instance. The application might then build a new instance for an expandable subtree. Then it might assign values to leaf attributes.
We might also want to delete an entire branch of the tuple tree. Suppose we have the following schema and corresponding tuple:
# Schema
Name
Address ( Street City State Zip Phones* )*
Phones ( Desc Number )*
# Tuple
Name = "Joe Rohn"
Address (
Street = "123 Anyway Dr."
City = "Georgetown
State = "Virginia"
Zip = "41908"
Phones = "(654) 111-1121"
Phones = "(654) 111-1122"
)
Address (
Street = "312 Anyway Dr."
City = "Georgetown
State = "Virginia"
Zip = "41908"
Phones = "(654) 111-1123"
Phones = "(654) 111-1124"
)
Phones (
Desc = "Home"
Number = "(654) 234-1232"
)
If we wish to view a table consisting of the
Address.Street and Address.Phones fields on this
tuple, we traverse the tuple tree and produce the following table:
| Address.Street | Address.Phones |
| 123 Anyway Dr. | (654) 111-1121 |
| 123 Anyway Dr. | (654) 111-1122 |
| 312 Anyway Dr. | (654) 111-1123 |
| 312 Anyway Dr. | (654) 111-1124 |
If we delete the branch of the tuple tree corresponding to the
Address field containing ``312 Anyway Dr.'' we also
implicitly delete the two phone numbers ``(654) 111-1123'' and
``(654) 111-1124'' associated with that
address.
We must be able to uniquely identify individual leaves in the tuple tree. Without this ability, we cannot construct the tree from the values nor can we tell which attribute values are related.
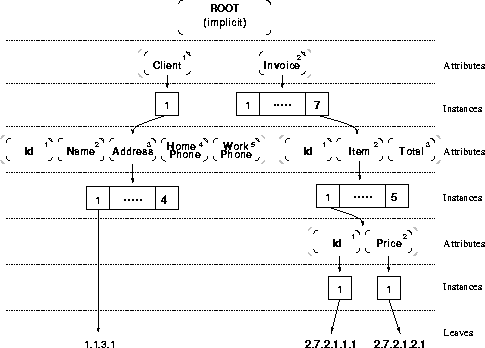
Figure 2: Enumerating the leaves of a tuple tree
A tuple tree has the following convenient properties: (1) each attribute node
has a unique local name (that distinguishes it from its siblings),
and (2) each instance node has a unique local number (that distinguishes it
from its siblings).
In Figures 1 and 2, attribute-node siblings are shown
surrounded by a gray box.
We number all the attribute-node siblings (within a single gray box) 1, 2, 3,
and so forth.
Then we assign each leaf a label formed by the concatenation
of the local numbers on the path from the root to that leaf, using a dot as a
separator, as shown in Figure 2.
The superscripts in the figure refer to the attribute number.
Therefore,
the first instance of Invoice.Item.Id (first item in the seventh invoice)
is labelled ``2.7.2.1.1.1''.
We call these leaf labels leaf identifiers.
Prefixes are called path labels.
Integers at odd positions in
a path label (that is, 2, 2, 1) are due to attribute numbers; integers
at even positions (7, 1, 1) are due to instance numbers.
We can think of each expandable Qddb attribute A as a separate
relational table.
The subattributes of A form the columns of the table.
(If A is not structured, the table has one column.)
In addition, the equivalent relational tables must contain
a link column with a unique identifier for joining with
other tables.
For example, an attribute A whose schema is A ( B C D )* is
a table with columns B, C, and D. A single tuple gives rise to several
rows in that table, one for each instance of attribute A.
Since both structured and non-structured attributes can be expandable, we can easily describe very complicated relationships between the tables. For example, we might have the following schema:
Location (
Name*
Address ( Street City State Zip Contact* )*
Phone ( Desc AreaCode Number )*
)
This Qddb example is equivalent to a relational Location table containing columns Name, Address, and Phone. The Address column contains unique identifiers linking it to a separate Address table, which contains, besides the link column, columns Street, City, State, Zip, and Contact. The Contact column contains unique identifiers linking it to a separate Contact table, which contains, besides the link column, a single data column. Similarly, the Name and Phone columns of the Location table are links to other tables. In all, there are five tables, interlinked with a web of unique identifiers.
The tuple tree is a convenient abstraction for manipulating related rows in possibly many relational tables. Relational rules may be enforced at the application level to ensure full compliance with the relational model (for example, to enforce non-empty fields or indivisible search values.) Any set of tuple trees can be decomposed into proper relational tables, although unique link fields must be invented when performing this decomposition. Any set of relational tables may also be composed into a set of tuple trees; existing link fields are extraneous and may be removed.
The tuple tree lets us construct all rows pertaining to the tuple without expensive join operations on large tables. The following algorithm produces all rows from a given node in a tuple tree:
procedure ProduceAttributes (AttributeNode) : set of rows
answer := NULL
for each Inst := instance of AttributeNode do
answer := union(answer, ProduceInstances(Inst))
return answer
procedure ProduceInstances (InstanceNode) : set of rows
if leaf(InstanceNode) then
return InstanceNode.Value
else
answer := NULL
for each Attr := attribute of InstanceNode do
answer := cartesian product(answer,
ProduceAttributes(Attr))
return answer
The union operator
returns a table that combines all the rows of its two operands, which agree
on number and type of columns.
The cartesian product operator returns a table that combines all the
columns of its two operands, with as many rows as the product of the rows of
the two operands.
We can build all the complete rows of the tuple tree for a given tuple:
ProduceInstances(RootNode)
We can also build partial rows pertaining to subtrees. For example, we could find all information about the 7th invoice for a particular tuple as follows:
ProduceInstances(2.7)
Invoice.Id Invoice.Item.Id Invoice.Item.Price Invoice.TotalThe values for the
Invoice.Id and Invoice.Total columns
are the same for all rows.
We can narrow our focus and consider only items in the 7th invoice:
ProduceAttributes(2.7.2)
Invoice.Item.Id and
Invoice.Item.Price.
Figure 3 depicts a tuple tree
for the schema A ( B C* D )*.
An invocation of
ProduceAttributes(RootNode)
| A.B | A.C | A.D |
| once | upon | dreary |
| once | midnight | dreary |
| while | pondered | weak |
| over | many | curious |
| over | quaint | curious |
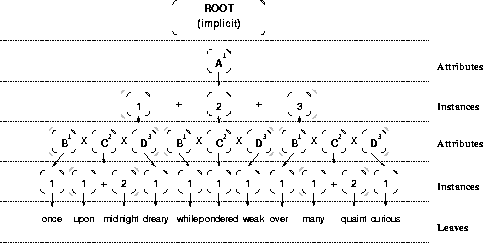
Figure 3: Traversing a tuple tree
Now suppose we aren't interested in the A.C attribute.
Excluding the undesired attributes from the traversal
builds the following table, which accurately restricts the previous one:
| A.B | A.D | |
| once | dreary | |
| while | weak | |
| over | curious |
Many database applications manipulate sparse data; that is, many fields are empty in any given tuple. One advantage of the tuple tree is that we can reconstruct the entire tuple tree from only those leaves containing data. Qddb's external representation only stores attributes with non-empty data. For example, consider the following modification of the tuple tree in Figure 3 to include fewer populated leaves:
| 1.1.2.1 | upon |
| 1.1.2.2 | midnight |
| 1.2.1.1 | while |
| 1.3.2.1 | many |
| 1.3.2.2 | quaint |
| 1.3.3.1 | curious |
From these leaves, we know there are three instances of attribute
A, the first and third of which contain two
instances of A.C. When Qddb reads in these leaves, it can build
an entire internal tuple tree. The algorithm for building tuple trees
from a given set of leaf values (each with a leaf identifier) is as
follows:
The implementation of this algorithm is most efficient when the leaves are presented in left-to-right order by leaf identifier. The external representation of Qddb data always maintains order because it is generated from a left-to-right depth-first traversal of an internal tuple tree.
Locking rows in a traditional relational database can be a non-trivial task. A set of related rows may be spread across many tables, requiring many locks. Locating the rows to lock may require queries on many tables.
A tuple tree is stored externally as a contiguous list of leaves. The entire contiguous region of the database file can be locked to achieve a lock on a given tuple. Qddb does not lock at a finer grain (such as a subtree of the tuple tree), although subtrees are also stored contiguously, and Qddb therefore could easily accomplish finer-grained locking. It is straightforward to lock multiple tuple trees if the need arises.