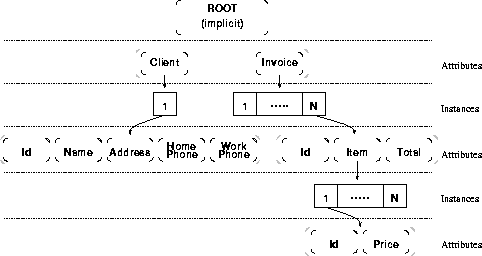
A Qddb schema defines the layout of data tuples in the database. The schema is in the form of a tree that we call the schema tree. Each individual tuple in the relation is represented in a corresponding tuple tree. Each branch of the schema tree may be associated with multiple copies in any given tuple tree. Each duplicate is called an instance. The leaves of the tuple tree hold the actual data.
To demonstrate these concepts, consider the following three tables in a traditional relational database:
Client Client Id Name Address Home Phone Work Phone 1 George Goodan 123 Hardy Rd 277-1234 278-5432 2 Joan Goodan 323 Hardy Rd 277-1234 278-5432 3 Henry Zellerman 378 Jaclynne Rd 262-6432 268-9678
Invoice Client Id Invoice Id Item Id Price 2 1 1232 $1.20 2 1 1233 $2.40 2 1 1121 $7.30 3 2 3214 $100.00
Invoice Total Invoice Id Invoice Total 1 $10.90 2 $100.00
In traditional relational databases, each table has its own schema. Each client may participate in multiple invoices; the Client and the Invoice tables are linked by the Client Id fields. If a client may have an arbitrary number of addresses or phone numbers, we could build new address or phone number tables and also link them by the Client Id field.
Presentation of data across tables is constructed by an appropriate join operation. For example, if we want to present a particular invoice, we (1) find the desired invoice in the Invoice table, (2) use the Client Id to find the corresponding client in the Client table, (3) use the Invoice Id to find the invoice total in the Invoice Total table, and (4) present this data in a usable form. These accesses represent a considerable amount of complex work for the application programmer. Complex work is both expensive and prone to errors, so we would like to eliminate as much of the complexity as possible.
The three tables shown above can be described in Qddb by a single schema tree. Because trees can be represented in a list form, and programmers are generally quite familiar with lists, we choose to represent our schema trees as lists. (End users do not need to see this representation.)
A Qddb schema is a set of attributes, where each attribute may contain other attributes. Here is the appropriate schema:
Client ( Id Name Address HomePhone WorkPhone )
Invoice ( Id Item ( Id Price )* Total )*
This list has two elements, Client and Invoice.
Each is an attribute of the schema.
Client is a structured attribute. It has five
subattributes, Client.Id, Client.Name,
and so forth. These have no subattributes of their own, so they are leaf
attributes and represent slots for data.
The asterisk `*' denotes that an attribute or subattribute is
expandable;
in other words, it may have any number of
instances . These expandable
attributes are equivalent to the joined tables shown earlier. Expandable
attributes may be structured;
their subattributes may themselves be structured and/or expandable.
. These expandable
attributes are equivalent to the joined tables shown earlier. Expandable
attributes may be structured;
their subattributes may themselves be structured and/or expandable.
In our example, Invoice is a structured, expandable attribute, and its
subattribute Invoice.Item is also both structured and expandable.
A tuple that obeys this schema may have many instances of Invoice, each
of which may have many instances of Invoice.Item.
In relational terms, the Qddb database contains the data from the several joined tables shown earlier. Each Qddb tuple corresponds to exactly one entry in the Clients table. That client may be associated with an arbitrary number of entries in the Invoices table. Each invoice contains an arbitrary number of items (each with its price) and a total.
To access an invoice with a particular identifier,
we only need to find the unique tuple that has an instance of
Invoice.Id with the appropriate value.
The associated instance of that tuple's Invoice attribute has all the
information we seek.
If we never plan to search invoices, clients, or items by their identifiers,
all Id fields are extraneous and may be removed.
Figure 1 shows a tuple tree for the schema tree presented above. Every branch of the tuple tree is a copy of a branch in the schema tree with instance nodes inserted between each level. If an attribute is expandable, there can be multiple instance nodes (1...n), each of which heads its own subtree. Leaf attributes also have instance nodes (not shown) that point to data.
The schema tree presented above is nearly as inflexible as original relational tables, although it is perhaps clearer. Suppose we want to associate each client with an unlimited number of addresses and phones. Further, suppose we want to associate some phone numbers with particular addresses and other phone numbers with no address at all (perhaps for mobile phones). The schema tree can be upgraded to cover these needs:
Client (
Id
Name
Residence ( Address Phone* )*
Phone ( Description Number )*
)
Invoice ( Id Item ( Id Price )* Total )*
To represent this schema in a tabular form would require six tables, the original three tables plus two different ones for phones and one for residences. Two new kinds of unique identifiers would be needed, one for residences and one for no-address phones. These identifiers would link the tables.
As the number of expandable fields increases, so does the number of tables required to represent them. For that reason, relational database designers tend to shy away from such data. The Qddb schema tree, however, allows us to specify the relational tables in an easily conceivable form. The application programmer doesn't have to worry about building multiple tables and setting up appropriate links between the tables, so expandable attributes are welcomed if they are appropriate.