The basic Qddb data abstractions are schemas, keylists, tuples, rows, views, and instances. Each of these datatypes refers to Qddb structures introduced in Chapter 4.
In this section, we will discuss these abstractions without descending into Tcl commands. The next section discusses the commands that manipulate these abstractions.
The schema is an abstraction of the Schema file in the Qddb relation directory. It represents the schema as a tree. (See Figure 7.1).
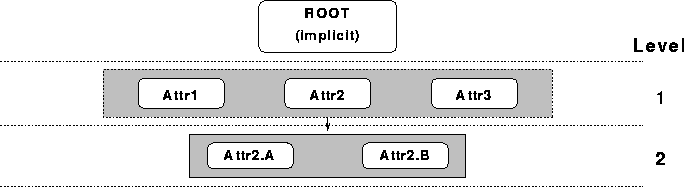
Figure 7.1: Tree Form of the Qddb Schema ``Attr1* Attr2 (A B)* Attr3''
The tree form implies two operations:
A keylist describes a set of tuples, often those that satisfy some query. Each node in the keylist refers to a tuple in the database (perhaps in the Database file, perhaps in a file in the directories Additions or Changes). Within the tuple, a keylist node can refer to a particular attribute. Keylists have several binary operations:

The Qddb query mechanism supports searches on individual attributes and on
entire tuples based on:
(1) a word, (2) a number, (3) a date, (4) a regular expression, and
(5) a range of words, numbers, or dates.
Each query returns a keylist; logical combinations of queries are accomplished
by binary operations on the resulting keylists.
For example, if you want to find
all the tuples that contain the word Joe and Machey,
you would:

Each keylist node is a quadruple {start, length, type, number} and a leaf identifier that points into the data files. The pair {type, number} specifies whether the tuple resides in the stable or instable part of the database. Not all nodes in a keylist necessarily point to a valid tuple; if a tuple has been changed or deleted, then a query might still match the stable tuple. Invalid tuples are empty when you try to read them.
The tuple is the basis for data manipulation. You can read, write, add, delete, and change tuples. You can also translate tuples from internal tree form into several other formats: external, tclexternal, and readable. A tuple can be locked to prevent others from writing it, but even a locked tuple can always be read. The act of writing a tuple is synchronization-atomic; Qddb will wait until any writes are complete before reading. When a tuple is locked for writing, it is refreshed from disk immediately after the lock is acquired so that you are guaranteed the latest version of the tuple.
Attr1 = "the"
Attr1 = "moon"
Attr2 (
A = "was"
B = "a"
)
Attr2 (
A = "ghostly"
B = "galleon"
)
Attr3 = "tossed"
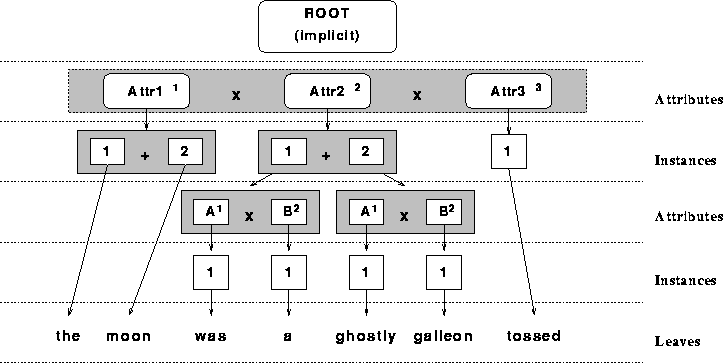
Figure 7.2: Tree Form of a Qddb Tuple
The operations on tuples include adding and removing instances of attributes.
The tuple shown in Figure 7.2 has two instances of Attr2.
You might wish to add another instance of Attr2 and fill in just the
B subattribute.
When you request a new instance of Attr2,
you will get a new branch of Attr2 that includes Attr2.A and
Attr2.B.
You can then fill in Attr2.B and leave Attr2.A empty.
When the tuple is stored,
the empty attribute will be omitted, and no storage will be
consumed.
A row is a view of a tuple that restricts each multiple-instance attribute to one of the instances. Rows are built from tuples. A complete row includes each leaf of the schema tree. A partial row omits some leaves. You would omit leaves if the data they contain is not important to display at the moment.
For example, the following is one complete row of the tuple shown in 7.1:
Attr1 = "the"
Attr2 (
A = "ghostly"
B = "galleon"
)
Attr3 = "tossed"
The following is a partial row of the same tuple:
Attr1 = "the"
Attr3 = "tossed"
Typically, you want to prune identical partial rows (you cannot have identical
complete rows![]() .)
.)
All complete rows can be extracted from a tuple tree with the following algorithm, written in an ad-hoc, C-like notation (see Figure 7.2):
rowList procedure ProcessAttributes (AttributeNode) {
rowList r = NULL;
foreach Inst = instance of attributeNode {
r += ProcessInstances(Inst) /* Union */
}
return r
}
rowList procedure ProcessInstances (InstanceNode) {
rowList r = NULL
if leaf(InstanceNode)
return InstanceNode.Value
else {
foreach Attr = attribute of InstanceNode
r *= ProcessAttributes(Attr) /* Cartesian product */
return r
}
}
rowList r = ProcessInstances(RootNode)
ProcessInstances with the root node of the
tuple. ProcessInstances iteratively forms
the cartesian product of the rows produced at that instance by
ProcessAttributes. ProcessAttributes iteratively forms the
union of all rows produced at that attribute by calling
ProcessInstances.
Consider the following animal-records schema:
Kind (
Desc*
Which
Breed
)*
Whose
Here is a tuple in that relation:
Kind (
Desc = "My dog's name is 'Bonnie'"
Desc = "My dog's name is 'Boomer'"
Which = "Dog"
Breed = "Shekie"
)
Kind (
Desc = "My cat's name is 'Vinnie'"
Desc = "My other cat's name is 'Bud'"
Which = "Cat"
Breed = "Domestic short hair"
)
Whose = "Eric"
The following are the complete rows of this tuple:

Partial rows can be
extracted by excluding particular columns from the result, possibly
deleting duplicate rows.
A newly-defined view initially corresponds to the first row, that is, the row that has the first instance of each attribute in the tuple. After definition, a view may be shifted to any row. The usual way is to switch to a different instance of an expandable attribute.
For example, using the Schema and tuple defined in Section 7.1.5, we might have the following view:

This view describes a row
containing the first instance of Kind and the first instance of
Kind.Desc within Kind. By shifting the
the Kind.Desc attribute to the second instance, the view becomes:

You can also shift the instance of the entire Kind attribute, in which
case the view would contain
the first instance of Kind.Desc within the second instance
of Kind:
