The straightforward ideas presented so far constitute basic qddb. In this section we describe enhancements to basic qddb, which generally involve creating optional new structure files at stabilization time in order to make certain types of access more efficient. If these structure files are missing, we disallow any query that would require them. Most of these enhancements were motivated by our SQLlike language, QSQL, to which we return in Section 6.
It is traditional in languages like SQL to base queries on characteristics of particular attributes, not of tuples as a whole. To add such a facility, we could join the attribute name to each word for the purpose of hashing. Unfortunately, it would no longer be easy to perform attribute-independent queries, and both HashTable and Index would grow.
We chose a less restrictive method for attribute-specific queries based on an extra structure file called AttributedIndex. For each key, AttributedIndex augments each locator with an identifier that describes the attribute in which the key occurs. Attributes are designated by enumerated attribute identifiers, which are single integers that provide a way to uniquely identify each attribute name in the Schema. This information is readily available at stabilization time and adds little overhead to the stabilization process. The corresponding AttributedTupleList data structure also decorates each entry by an enumerated attribute identifier.
There is no extra system call overhead involved with this method. The only performance penalties are: (1) space: AttributedIndex is slightly larger than Index to accommodate reduced attribute identifiers and some new entries (if the same word appears in several attributes of the same tuple), and (2) time: Uninteresting nodes must be deleted from any AttributedTupleList before tuples are read from the relation.
Depending on the expected queries, relations may be stabilized with either or both of Index and AttributedIndex.
Basic qddb searches on keys. Instead, an SQL query might be posed
with respect to a
regular expression to be matched directly against attribute values.
For example, searching for the pattern
``\(606\)-293-([0-9][0-9][0-9][0-9])''
should produce a list of telephone numbers in a particular city zone.
Regular expression searching usually requires a linear search of all text in the relation. Some regular expressions are simple enough that they are essentially equivalent to an intersection of ordinary word queries. For example, the regular expression ``operating systems'' is almost equivalent to the intersection of the queries ``operating'' and ``systems'', although the intersection will include tuples that contain these words in nonadjacent or reversed positions.
Reducing the regular expression to ordinary queries is often inadequate. Regular expressions cannot make use of hash tables, so we need another way to narrow the search. It might seem reasonable to search linearly through Index, but that file is often longer than Stable, since it contains lists of locators.
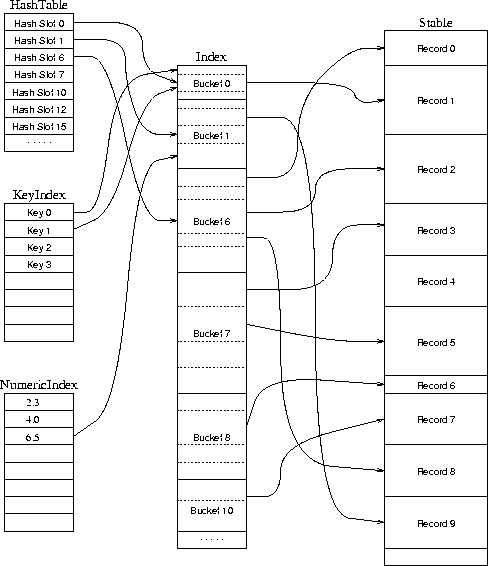
Instead we rely on a new optional structure file, KeyIndex, consisting of a single locator into the Index file for each key. (See figure 6.) KeyIndex is meant to be searched linearly. Regular expressions to be matched within a single key are matched against all the keys in the KeyIndex file. However, regular expressions that are meant to cross key boundaries (or involve non-key punctuation) must still be applied to the Stable file and any instable parts of the relation. We have observed that the size of KeyIndex is only about 15-35% the size of Index and about 20-30% the size of Stable, so the time savings are significant for appropriate regular-expression queries.
The expense of this method is two open system calls and
![]()
read system calls. An extra read of Index is required for each key found. When it is possible to read the entire list of keys into memory, the computation required for regular expression searching will be proportional to the number of keys in the relation, and the number of reads will be one plus the number of entries found. The amount of computation required for regular expression searches is, of course, large.
SQL allows queries that treat attributes as numbers for comparison testing. In order to handle such queries, we introduce another optional structure file, NumericIndex, which contains a sorted list of numeric keys (represented in Ascii, decimal fixed point), each with a locator into Index. (See figure 6.) A query program can then perform a binary search on NumericIndex to construct a TupleList matching any numerical range or set of ranges. This binary search may read all of NumericIndex and perform an internal search or may probe it as an external data structure until the region of interest is small enough to read into memory. Similarly, we use KeyIndex (defined above), which we sort alphanumerically, for range searches of arbitrary strings.
Large relations tend to have large hash tables. The space problem is more severe when we run an SQL query that accesses several relations at once. We wish to keep the memory requirements of query programs as small as possible so that small machines can be used for queries, even though larger ones might be needed for stabilization.
We therefore allow an optional replacement for the HashTable structure file called RandomHashTable. This table contains the same information as HashTable, but each entry has a fixed length, empty entries are not omitted, and we omit recording each hash-bucket number. When this table is present, query programs access individual hash table entries on demand without reading and saving the entire table. They may cache entries if they wish.
The time penalty that we incur is an occasional single read of the RandomHashTable file or a search through the cashed entries on each query. The space penalty is that RandomHashTable is generally considerably larger than HashTable because it does not suppress empty entries and because each entry must be lengthy enough to hold the largest entry.
The values in Stable tend to occupy only a part of the file. The attribute and instance identifiers (such as %3.2.1.1.3.1) sometimes require more storage than the actual data. In one genealogical database we have designed, more than 40% of the Stable file is occupied by non-value information.
Since the identifiers are usually very repetitious, we can abbreviate them for storage efficiency. The association between abbreviations and full identifiers is stored in an optional Abbreviations file. The set of abbreviations needed is discovered at stabilization time. The Stable file only uses these abbreviations, leading to a significant potential space savings, especially in large relations with deeply nested attribute structures. Entries in the Changes and Additions directories may use abbreviations where appropriate, or full identifiers where desired.
The performance penalty, which involves reading Abbreviations once and then performing constant-time array lookup, is incurred only by those programs that deal with presentation format. The identifiers are not necessary for storage-format programs.